| <<Prev | TOC | Next>> |
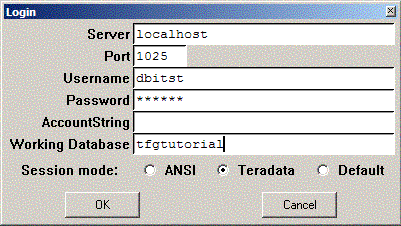
From the File menu, click New... and then click Project. When requested, enter your logon information as before, but this time, also add the database you're using for the tutorial:
You'll need this when you load a stored procedure definition later. Click OK to login and proceed. As before, the New Project dialog is displayed:
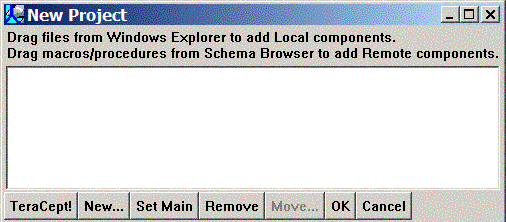
For this example, you'll create a new script from scratch, rather than load a pre-existing script. Click the New... button; the following New Component dialog will be displayed:
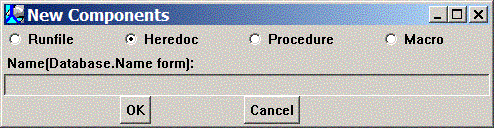
Select Heredoc from the radiobutton list. The Name(Database.Name form) entry in the dialog remains disabled, since you aren't creating a new database macro or procedure. Click the OK button to create a new template BTEQ heredoc. You'll be presented with a File Save dialog. Navigate to your TeraForge tutorial directory, and, since we're creating a new file, enter the name "autocapper.btq" in the File name: entry and click Save. (NOTE: if autocapper.btq already exists in your tutorial directory, then a confirmation message will be displayed asking if you wish to overwrite the existing file; simply click Yes, unless you need to save the file.).
You should now see an updated New Project dialog with your "autocapper.btq" file added to it:
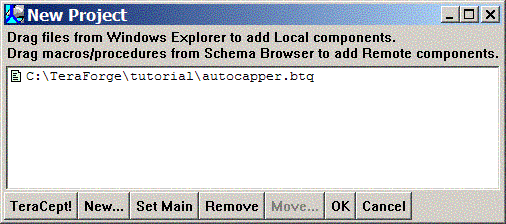
Since this is the only component you're adding for now, doubleclick on the autocapper.btq icon, then click Set Main, and confirm the selection as before. Finally, click OK to present the project file save dialog. Navigate to your tutorial directory, then enter 'autocapper.tfg' in the File name: entry, and click Open to create the new project file.
Once the new project has been created, a new template heredoc script is created in the Source Window:
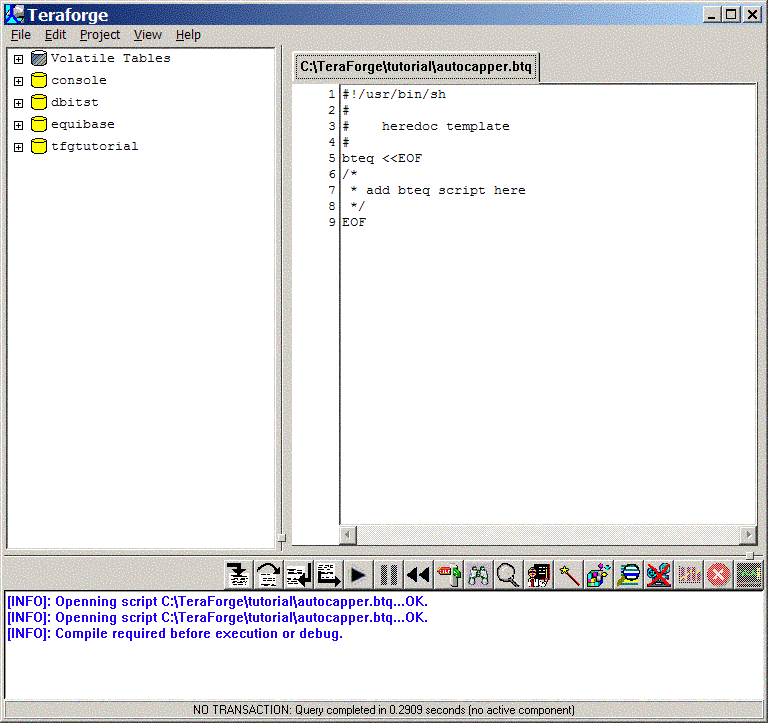
Obviously, you want to add more to this. For this tutorial, simply copy and paste the following script text into the template script window:
#!/usr/bin/sh
#
# sample handicapping script for TeraForge tutorial
#
bteq <<EOF
.logon ${MYLOGON}
database ${MYDATABASE};
/*
* load today's race entries: for now, just pull
* the entries for the last date in our
* races table
*/
insert into ${MYDATABASE}.todays_entries
select TRACK,
RACENUM,
HORSE,
JOCKEY,
TRAINER,
ENTRYNUM,
POSTNUM,
ODDS,
WEIGHT,
MEDS_EQUIP
from ${MYDATABASE}.entries
where track='HOL' and racedate = '2002-06-01';
/*
* load today's races
*/
insert into ${MYDATABASE}.todays_races
select track, racenum, racetype, raceclass, purse, distance, surface
from ${MYDATABASE}.races
where track='HOL' and racedate='2002-06-01';
/*
* now generate the PPs for today's entries
* only use the 5 most recent races
*/
insert into ${MYDATABASE}.todays_pps
select a.track,
a.racedate,
a.racenum,
a.horse,
b.racetype,
b.raceclass,
b.purse,
b.distance,
b.surface || ' ' || b.trackcond,
a.jockey,
a.trainer,
a.final_position,
a.style,
k.winners,
b.fraction1,
c.avgfrac1,
b.fraction2,
c.avgfrac2,
b.fraction3,
c.avgfrac3,
b.fraction4,
c.avgfrac4,
b.fraction5,
c.avgfrac5,
a.race_comment
from
(select * from ${MYDATABASE}.entries
where racedate < '2002-06-01') a
join ${MYDATABASE}.todays_entries t
on a.horse=t.horse
join
(select * from ${MYDATABASE}.races
where racedate < '2002-06-01') b
on a.track=b.track and
a.racedate=b.racedate and
a.racenum=b.racenum
join ${MYDATABASE}.trackpars c
on b.track=c.track and
b.surface=c.surface and
b.distance=c.distance and
b.racetype=c.racetype and
b.raceclass=c.raceclass
left join ${MYDATABASE}.keyraces k
on a.track=k.track and
a.racedate=k.racedate and
a.racenum=k.racenum
qualify rank() over (
partition by a.horse
order by a.racedate desc) <= 5;
/*
* now execute the procedure for each track
* note we export as a HTML report file
*/
.export report file=C:\TeraForge\tutorial\hol_entries.html
call ${MYDATABASE}.autocapper('HOL', pphtml);
.export reset
.quit
EOF
Your Source Window should now look like:
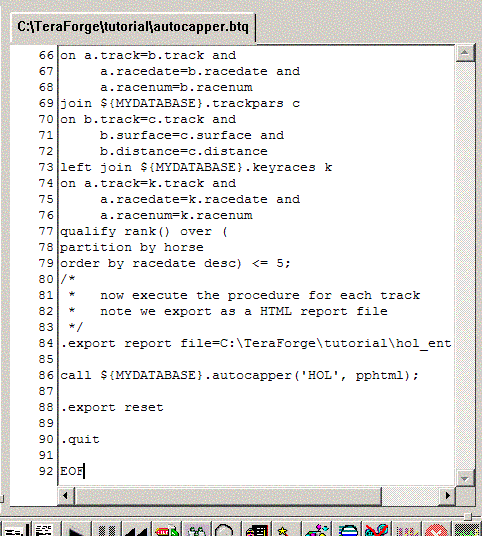
Note that the script references a stored procedure autocapper, but that component hasn't been added or created in the project yet. You're going to let TeraForge do some of the heavy lifting for you.
Click on the Project menu and click Compile. As the compile begins, you will once again be asked for definitions of the shell variables; enter them as you did before and click OK.
At this point, you should see a dialog like this:
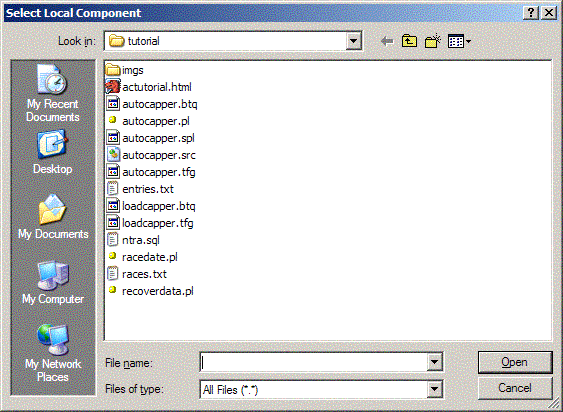
Also note the output in the Results Windows:
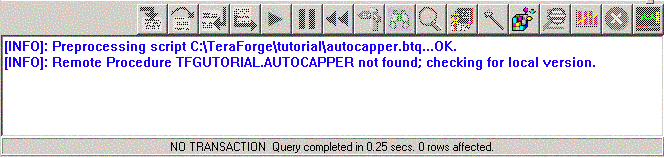
This dialog attempts to resolve any undefined component references and automatically pull them into your project. For example, if a macro or procedure already exists in the DBMS, either in the current working database, or using its fully qualified name, then the component will be added to the project, and a Source Window notebook page will be created for it (Note that no page is added for procedures which do not have source saved). For scripts, if the script name is fully qualified, and the file exists, then it will also be pulled into the project; if the script filename is not fully qualified, then TeraForge will use the current working directory as the root pathname to try to locate the file.
Fortunately, this tutorial includes a file with the stored procedure already defined. In the Select Local Component dialog, click on autocapper.spl, then click Open. The stored procedure will be added to the Source Window and compilation continues to completion.
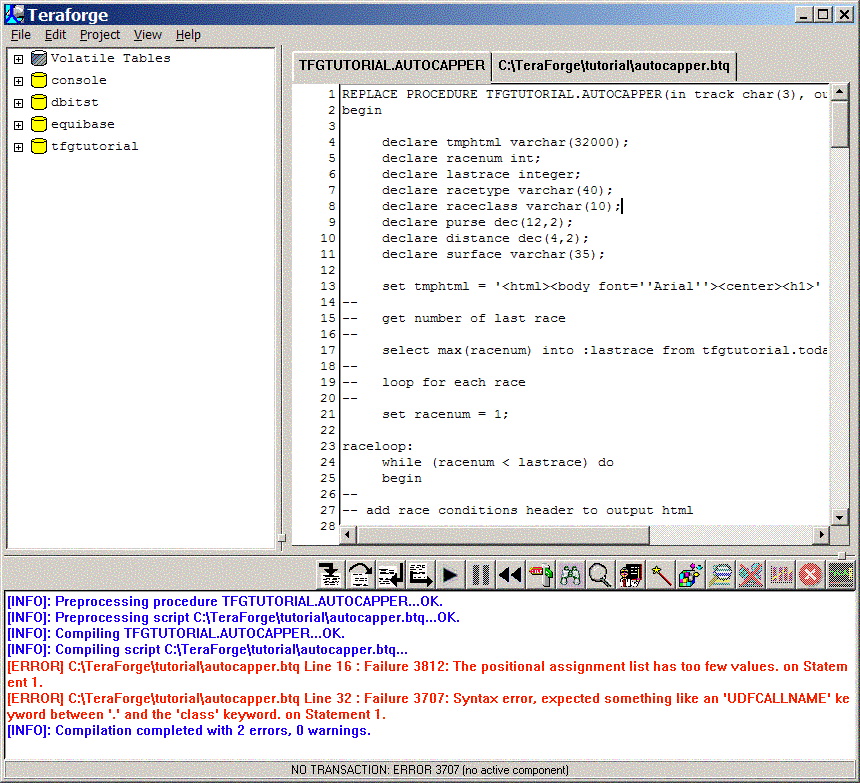
Oops, you've got some errors to fix!
Part of the compilation process for local procedures or macros includes compilation on the target database system. Project compilation will not complete successfully until components can be compiled on the DBMS (with the exception of "missing database object" errors in scripts). A side effect of this process is that a local macro or procedure will also exist remotely if it compiles successfully. Later on, we'll learn how to remove the remote instance, or to migrate a local component to a remote component.
But first, you need to fix the errors.
You'll fix the last error first, and then see how to use drag-and-drop editting to fix the first error.
To fix the error at line 32, if you scroll down a few lines, you'll see the "b.class," line that is causing your problem. Looking at the SELECT statement closely, you can see that table alias b is associated with a SELECT from the tfgtutorial.races table. Using the Schema Browser, expand the tfgtutorial.races table node. Alas, there is no "class" column, but there is a "raceclass" column. So simply change the "b.class" to "b.raceclass" in our script.
To fix the error at line 16, you'll use drag-and-drop editting:
We still have some cleanup to do. You'll need to add commas after all the columns you added, and remove the columnnames that were in the statement before. Finally, you have one column with different names in the source and target tables. TODAYS_ENTRIES.MORNINGLINE is sourced from the ENTRIES.ODDS column, so modify that column name.
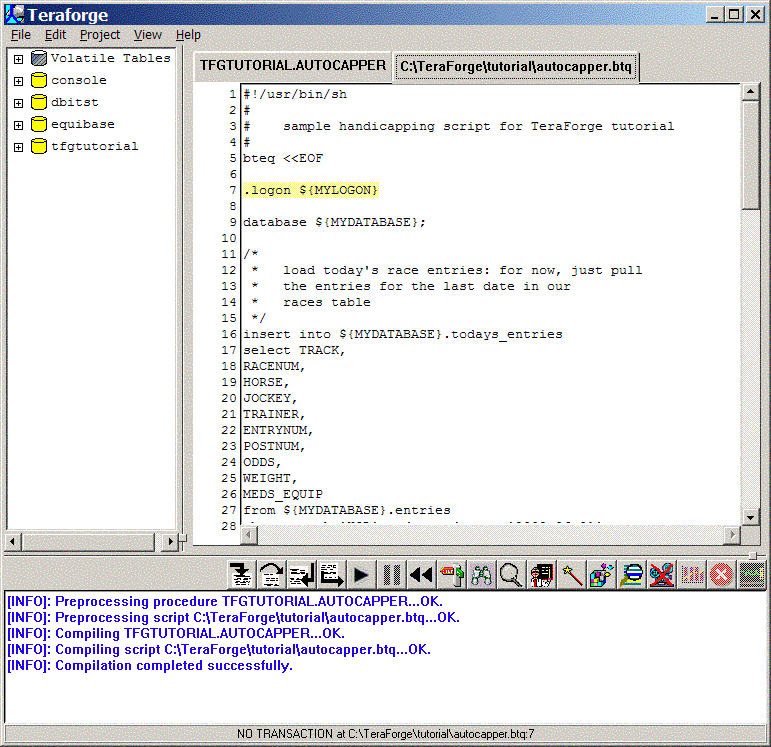
After fixing those errors, use the Project->Compile menu to recompile. The project should now be successfully compiled:
Now you can start debugging. After clicking on the CALL statement
within the Source Window at line 95, click on the Toggle BP
 button in the
button bar to set a breakpoint:
button in the
button bar to set a breakpoint:
Now click the Continue button. Execution
should proceed to the breakpoint and stop. Now click Step Into
button. Execution
should proceed to the breakpoint and stop. Now click Step Into
 . The source notebook should raise
the autocapper stored procedure to the top, with the first statement
highlighted as the current statement:
. The source notebook should raise
the autocapper stored procedure to the top, with the first statement
highlighted as the current statement:
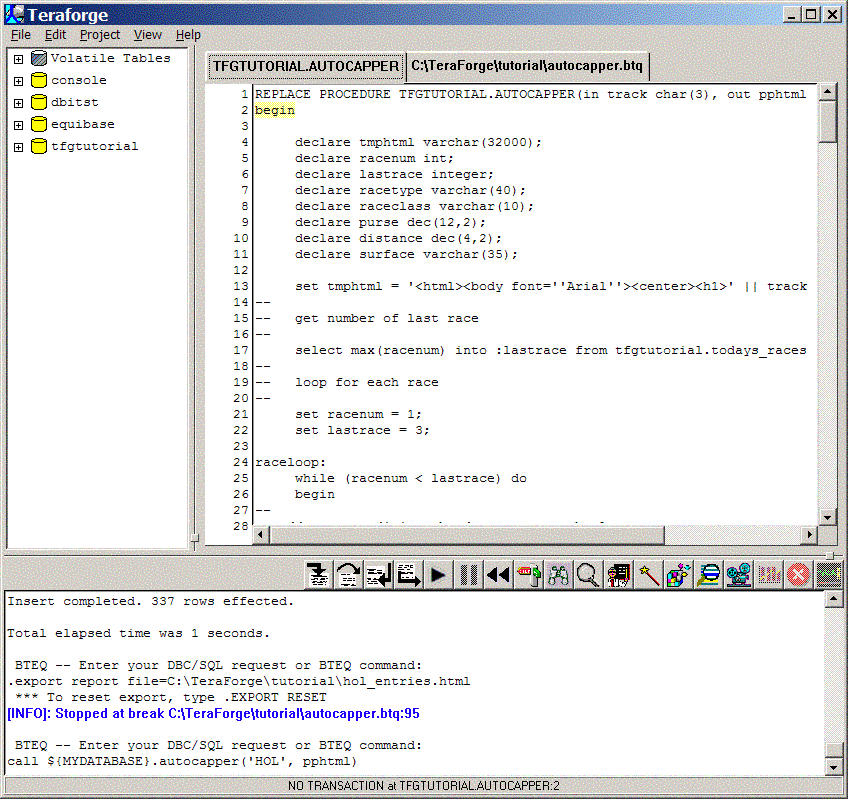
You can now single step, or set breakpoints within the stored procedure and continue. Let's set a breakpoint at the line 25 (the "while" statement) of the stored procedure:
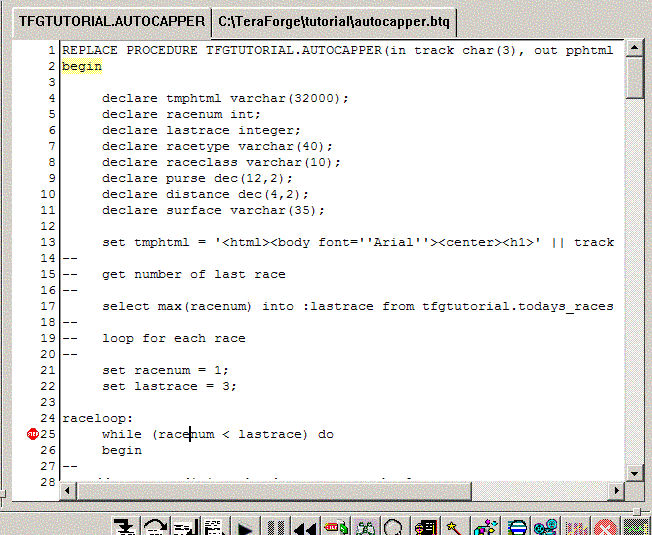
Now click Continue and let the procedure
run to the breakpoint. At this point, you've assigned some values
to local variables, so take a look at the call stack.
Click on View Stack :
:
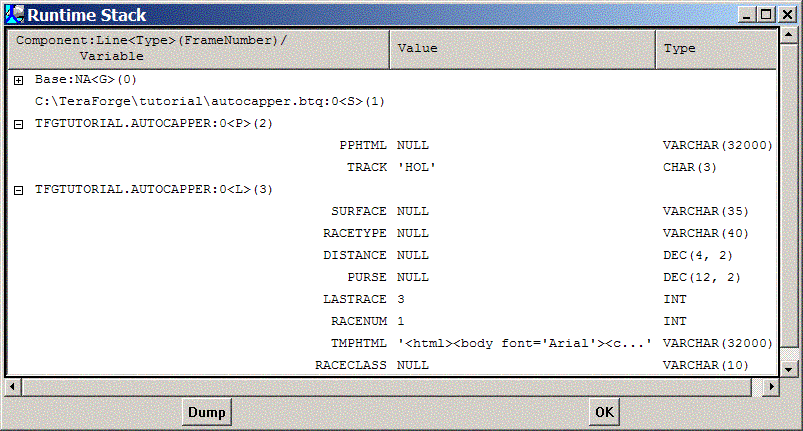
(Note: this image has the individual frames opened to display the variables/parameters associated with each frame)
Stack frames are displayed starting at the base frame (containing the global SQLSTATE, SQLCODE, ACTIVITY_COUNT, and ERRORLEVEL variables), continuing down the display, with the current topmost frame at the bottom of the display. In this example, there are 3 additional frames:
Note that the variables/parameters have their current value, and their type, listed to the right. Values for CHAR, VARCHAR, CLOB, BYTE, VARBYTE, or BLOB variables only display their first 30 characters or 15 bytes; NULL items will display NULL.
If you need to see the full text of a lengthy VARCHAR variable, you can simply double click on it within the stack view and it will be displayed in a dialog. Double-click on the TMPHTML variable; the following dialog should be displayed:
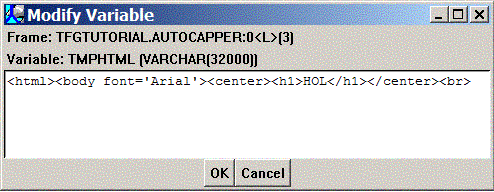
Suppose you found a minor error in our HTML formatting, but want to continue your debug session without modifying the source, recompiling, and restarting the debug session. The Modify Variable dialog allows you to modify the variable value at runtime. Click inside the dialog somewhere, and insert or delete some text as you wish:
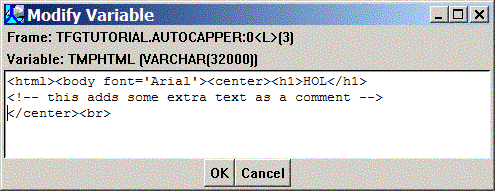
then click the OK button, and the new variable value is applied. This process works for any variable, or for IN and INOUT parameter values as well.
Close the Stack View by clicking OK. You can leave the Stack View open during execution, and watch as the various variable values change, and frames are added or removed from the stack, but that feature significantly slows down execution, so it should only be used when you really need to view those changes.
Let's finish running the project by clicking the
Continue button. The
AUTOCAPPER procedure contains a few PRINT statements;
as the procedure executes, the PRINT statements are
evaluated and displayed in the Results Window.
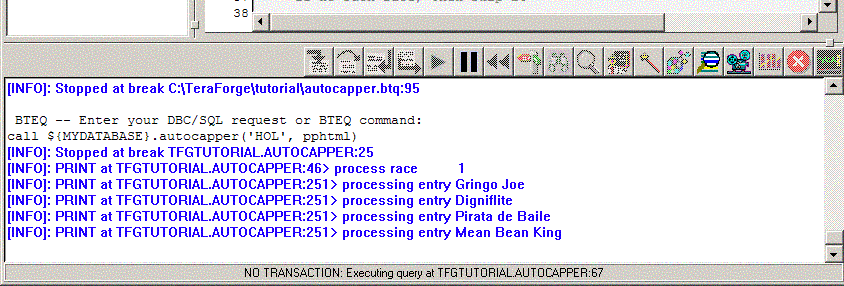
-- TFGPRAGMA PRINT 'this is a ' || some_variable || 'print pragma';
As procedure execution proceeds, the breakpoint at line 25 is
hit and execution stops. When that occurs, click on line 25,
and then click the Toggle Breakpoint
button to remove the break point,
and click the Continue button again
to let the project run to completion.
Now the project execution is finished, and the Results Window indicates the project completed successfully:
But just to make sure, open the EXPORTed report data in a text editor and see what it looks like:
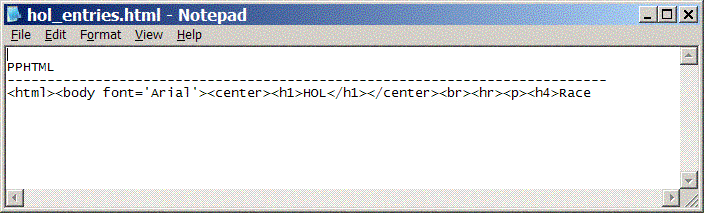
Hmm. Unfortunately, BTEQ doesn't provide a method to output a large string in a way you can easily read it. However, you could:
Note: A future release of TeraForge will support PTEQ, which will support more flexible/powerful data export.
Looks like we're ready to head to the track!
So click the File->Exit menu. First, you're asked to confirm that you want to exit. Click OK. After confirming the exit, you're asked if you want to save your project. By clicking Yes, you'll be saving your current project context, including any currently defined breakpoints and environment variable values. In addition, you'll be asked if you wish to save any components that have been modified since the component was opened. Click Yes to all of these dialogs. Finally, you're presented with the Component Relocation dialog:
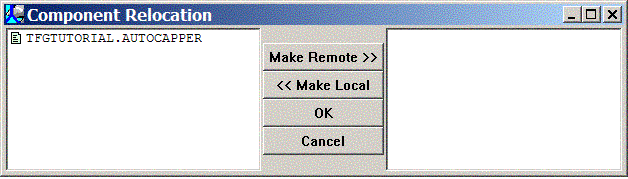
When you save or close a project that contains local macro or procedure components that have compiled successfully on the DBMS, a dialog is presented which allows you to convert those local components to remote components, i.e., the next time you open the project, TeraForge will load the converted component's text directly from the DBMS. Likewise, you may choose to convert remote components to local components (e.g., to edit or review the the component outside of TeraForge); in that instance, copies of the remote component will be written as local files.
When a project is closed:
For the next tutorial, you'll be importing the procedure as a remote component into a new project, so lets make the procedure a remote component. Simply use your mouse to select the procedure in the Local Pane on the left side of the dialog, then click the Make Remote >> button. The procedure should have moved from the Local Pane on the left to the Remote Pane on the right side of the dialog. Click OK to complete the migration, and close the dialog.
TeraForge then exits completely.
| <<Prev | TOC | Next>> |